
builder
EKS 스케일링의 강자 Karpenter 본문
EKS에는 기본적으로 Cluster Autoscaler가 있다. Karpenter가 나오기 전에 유일하게 노드를 확장해주는 방식으로, 여러 프로바이더를 지원한다.그러나 CA는 하나의 자원을 두 주체(ASG, EKS)가 각자의 방식으로 관리하기 때문에 관리 정보에 싱크가 맞지않아 여러 문제가 발생한다.
대표적으로 EKS에서 노드를 삭제해도 인스턴스(노드)가 삭제되지 않는 현상이 있다. 또한, CA의 노드 스케일인 옵션이 적고 느리다.
CA의 문제점들
- AWS Auto scaling에만 의존하여, 직접적인 노드 삭제와 생성이 안됨
- EKS에서 노드 삭제해도 인스턴스가 삭제되지 않음
- 노드 축소 시, 특정 노드 축소가 어려움
- Pulling 방식이기 때문에 API 제한이 걸릴 수 있음
- 스케일링 속도가 아주 느림
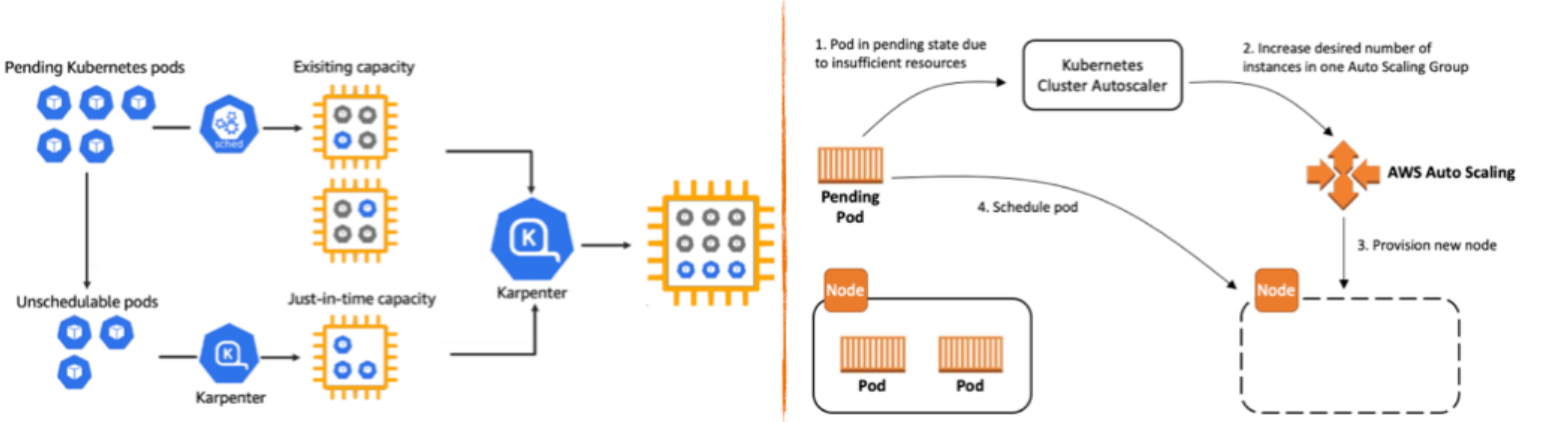
Karpenter
karpenter는 이런 CA의 문제들을 해결할 수 있다. 비교적 출시된지 얼마 안되었기 때문에 자료가 없지만, 퍼포먼스는 매우 뛰어나다.

Karpenter는 pod 스케쥴링 이벤트가 pub-sub 방식이기 때문에 API 영향이 없으며, 바로 대응하기 때문에 레이턴시가 있는 Pulling보다 속도가 빠르다. 스케쥴링 안된 Pod를 발견하면 바로 노드를 생성할 수 있고, 비어있는 노드는 발견하면 즉각 제거한다.
Kubernetes 커스텀 리소스기 때문에 ArgoCD로 배포가 가능하며, Yaml에 선언된 다양한 Provisioner를 활용 가능하다.
Provisioner
프로비저널은 노드와 노드를 통해 실행되는 파드의 제약조건을 의미한다. 하나의 Karpenter에는 하나 이상의 프로비저너가 구성되어야하며, 구성된 프로비저너는 karpenter에 의해서 반복된다. 가능한 설정은 아래와 같다.
- karpenter가 만드는 노드에서 실행되는 파드를 taint 정의로 제한
- 노드 생성을 특정 영역, 인스턴스 유형으로 제한
- 초기 taint 정의
(아래는 provisioner yaml 템플릿 파일)
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
# References cloud provider-specific custom resource, see your cloud provider specific documentation
providerRef:
name: default
# Provisioned nodes will have these taints
# Taints may prevent pods from scheduling if they are not tolerated by the pod.
taints:
- key: example.com/special-taint
effect: NoSchedule
# Provisioned nodes will have these taints, but pods do not need to tolerate these taints to be provisioned by this
# provisioner. These taints are expected to be temporary and some other entity (e.g. a DaemonSet) is responsible for
# removing the taint after it has finished initializing the node.
startupTaints:
- key: example.com/another-taint
effect: NoSchedule
# Labels are arbitrary key-values that are applied to all nodes
labels:
billing-team: my-team
# Annotations are arbitrary key-values that are applied to all nodes
annotations:
example.com/owner: "my-team"
# Requirements that constrain the parameters of provisioned nodes.
# These requirements are combined with pod.spec.affinity.nodeAffinity rules.
# Operators { In, NotIn } are supported to enable including or excluding values
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["c", "m", "r"]
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["4", "8", "16", "32"]
- key: "karpenter.k8s.aws/instance-hypervisor"
operator: In
values: ["nitro"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-west-2a", "us-west-2b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type" # If not included, the webhook for the AWS cloud provider will default to on-demand
operator: In
values: ["spot", "on-demand"]
# Karpenter provides the ability to specify a few additional Kubelet args.
# These are all optional and provide support for additional customization and use cases.
kubeletConfiguration:
clusterDNS: ["10.0.1.100"]
containerRuntime: containerd
systemReserved:
cpu: 100m
memory: 100Mi
ephemeral-storage: 1Gi
kubeReserved:
cpu: 200m
memory: 100Mi
ephemeral-storage: 3Gi
evictionHard:
memory.available: 5%
nodefs.available: 10%
nodefs.inodesFree: 10%
evictionSoft:
memory.available: 500Mi
nodefs.available: 15%
nodefs.inodesFree: 15%
evictionSoftGracePeriod:
memory.available: 1m
nodefs.available: 1m30s
nodefs.inodesFree: 2m
evictionMaxPodGracePeriod: 60
imageGCHighThresholdPercent: 85
imageGCLowThresholdPercent: 80
cpuCFSQuota: true
podsPerCore: 2
maxPods: 20
# Resource limits constrain the total size of the cluster.
# Limits prevent Karpenter from creating new instances once the limit is exceeded.
limits:
resources:
cpu: "1000"
memory: 1000Gi
# Enables consolidation which attempts to reduce cluster cost by both removing un-needed nodes and down-sizing those
# that can't be removed. Mutually exclusive with the ttlSecondsAfterEmpty parameter.
consolidation:
enabled: true
# If omitted, the feature is disabled and nodes will never expire. If set to less time than it requires for a node
# to become ready, the node may expire before any pods successfully start.
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
# If omitted, the feature is disabled, nodes will never scale down due to low utilization
ttlSecondsAfterEmpty: 30
# Priority given to the provisioner when the scheduler considers which provisioner
# to select. Higher weights indicate higher priority when comparing provisioners.
# Specifying no weight is equivalent to specifying a weight of 0.
weight: 10참고할 만한 설정은 Subnet, Security group, instance type, tag, Storage, AMI가 있다. 여기서 AMI를 설정하지 않는다면 최적화된 AMI를 자동으로 설정해준다고 한다.
# Requirements that constrain the parameters of provisioned nodes.
# These requirements are combined with pod.spec.affinity.nodeAffinity rules.
# Operators { In, NotIn } are supported to enable including or excluding values
requirements:
- key: "karpenter.k8s.aws/instance-category"
operator: In
values: ["c", "m", "r"]
- key: "karpenter.k8s.aws/instance-cpu"
operator: In
values: ["4", "8", "16", "32"]
- key: "karpenter.k8s.aws/instance-hypervisor"
operator: In
values: ["nitro"]
- key: karpenter.k8s.aws/instance-generation
operator: Gt
values: ["2"]
- key: "topology.kubernetes.io/zone"
operator: In
values: ["us-west-2a", "us-west-2b"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64", "amd64"]
- key: "karpenter.sh/capacity-type" # If not included, the webhook for the AWS cloud provider will default to on-demand
operator: In
values: ["spot", "on-demand"]Instance type은 가드레일 방식으로 여러개 선언이 가능하다. 여기서 values에 spot과 on-demand 두 방식을 동시에 선언하게 되면 spot으로 생성되지만 없으면 on-demand로 설정된다.
여기서 스팟 선택 시엔 최대한 오래 유지될 수 있거나, 저렴한 인스턴스로 띄우게 된다.
# Resource limits constrain the total size of the cluster.
# Limits prevent Karpenter from creating new instances once the limit is exceeded.
limits:
resources:
cpu: "1000"
memory: 1000Giauto-scaling은 단일 인스턴스기 때문에 갯수 기준으로 노드의 limit을 정한다. 반면에 karpenter는 인스턴스 개수 기준이 아닌, CPU와 Memory 기준으로 limit을 정한다.
일반적으로 CA를 사용할 때는 PV 때문에 단일 서브넷에 노드 그룹을 만든다. 그러나 Karpenter를 사용하면 자동적으로 PV가 존재하는 서브넷에 노드를 생성하기 때문에 안정적으로 운영이 가능하다.
# If omitted, the feature is disabled and nodes will never expire. If set to less time than it requires for a node
# to become ready, the node may expire before any pods successfully start.
ttlSecondsUntilExpired: 2592000 # 30 Days = 60 * 60 * 24 * 30 Seconds;
# If omitted, the feature is disabled, nodes will never scale down due to low utilization
ttlSecondsAfterEmpty: 30추가적으로 ttlSecondsUntilExpired와 ttlSecondsAfterEmpty도 노드 디프로비저닝에 아주 유용한 설정값이다.
- ttlSecondsUntilExpired : 노드에 데몬셋을 제외한 모든 Pod이 존재하지 않을 때, 지정된 값 이 후 자동으로 정리됨 (안쓰면 삭제)
- ttlSecondsAfterEmpty : 설정한 기간이 지난 노드는 자동적으로 cordon, drain 처리되어 삭제됨. (주기적인 삭제로 노드 업데이트)
결론적으로 Karpenter를 사용하면 노드 최적화를 통한 비용절감에 굉장히 효과적이다. 유휴 노드는 알아서 정리해주고, 비용적으로 계산하여 노드를 합치거나 분리시키기도 한다. 리소스 할당량이 늘어나기 때문에 불필요한 리소스를 낭비하지 않게된다.
그러나 리소스 할당량이 클 경우, 아무리 스케일링 속도가 빠르다 한들 갑자기 늘어나는 트래픽을 감당하지 못할 수 있다. (Karpenter의 노드와 데몬셋 생성의 스케일링 속도는 대략 1~2분 사이라고함)
그럴 땐 오버 프로비저닝을 설정해서 증설용 깡통 Pod를 만들어 여유 공간을 확보해야한다.
'DevOps > Kubernetes' 카테고리의 다른 글
| Istio 서비스메시에 대해서 알아보자! (0) | 2023.07.07 |
|---|---|
| Karpenter의 Provisioner (0) | 2023.07.02 |
| EKS Ingress 생성 시 failed to retrieve credentials, sts:AssumeRoleWithWebIdentity 오류 해결하기 (0) | 2023.05.17 |
| EKS ALB Controller 생성 후, ALB Ingress 배포하기 (0) | 2023.05.17 |
| EKS Kubeconfig 다중 클러스터 적용하기 (0) | 2023.03.07 |



