
builder
Kafka 기본 개념 정리 본문
여러 곳을 찾아봐도 깔끔하게 개념을 이해할 수 있는 정리된 자료가 없어서 직접 정리해보려고 한다. kafka는 높은 처리량과 가용성, 확장성을 지니고 있지만, 의외로 구조는 간단하기 때문에 쉽게 이해할 수 있으리라 생각함.
카프카를 구성하는 주요 요소들
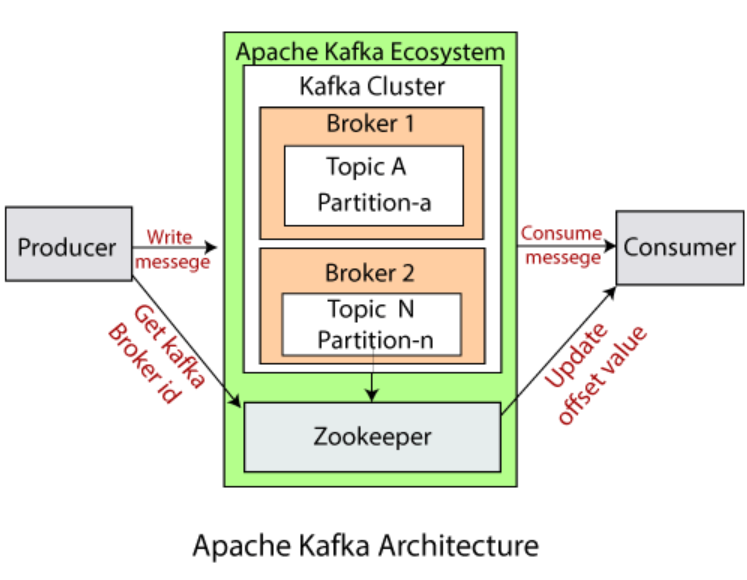
1) 주키퍼(Zookeeper)
카프카의 메타데이터를 관리하고 브로커의 health check를 담당하는 역할을 한다. 주키퍼는 여러 대의 서버를 클러스터로 구성한다. 그래서 살아 있는 노드가 과반수 이상이면 유지될 수 있다.
그래서 홀수로 구성되어야 한다. Znode를 통해서 카프카의 메타정보가 주키퍼에 기록된다. 주키퍼는 지노드를 이용하여 브로커의 노드 관리부터, 토픽과 컨트롤러를 모두 관리할 수 있다.
2) 카프카(Kafka)
카프카 클러스터(Cluster)라고도 한다. 프로젝트 어플리케이션의 이름으로 여러 대의 브로커를 구성한 클러스터를 의미한다.
3) 브로커(Broker)
카프카 어플리케이션이 설치된 서버, 노드를 말한다.
4) 프로듀서(Producer)
카프카로 메시지를 보내는 클라이언트를 말한다.
프로듀서는 카프카로 레코드를 전송할 때, 특정 토픽으로 메시지를 전달한다. 그래서 레코드에서 '토픽'과 '메시지 내용'은 필수값이다. 추가로 특정 파티션을 지정하기 위한 '레코드의 파티션'과 파티션의 레코드 정렬을 위한 '키'는 선택사항이다.
5) 컨슈머(Consumer)
카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트를 말한다.
컨슈머는 하나 이상의 컨슈머들이 모여 있는 컨슈머 그룹에 반드시 속하게 된다. 컨슈머 그룹은 파티션의 리더에게 토픽에 저장된 메시지를 요청한다. 여기서 파티션 수와 컨슈머 수는 일대일로 매핑되는 것이 가장 좋다.
6) 토픽(Topic)
카프카는 메시지를 토픽으로 구분하고, 각 토픽은 카프카에서 고유한 이름을 가진다.
7) 파티션(Partition)
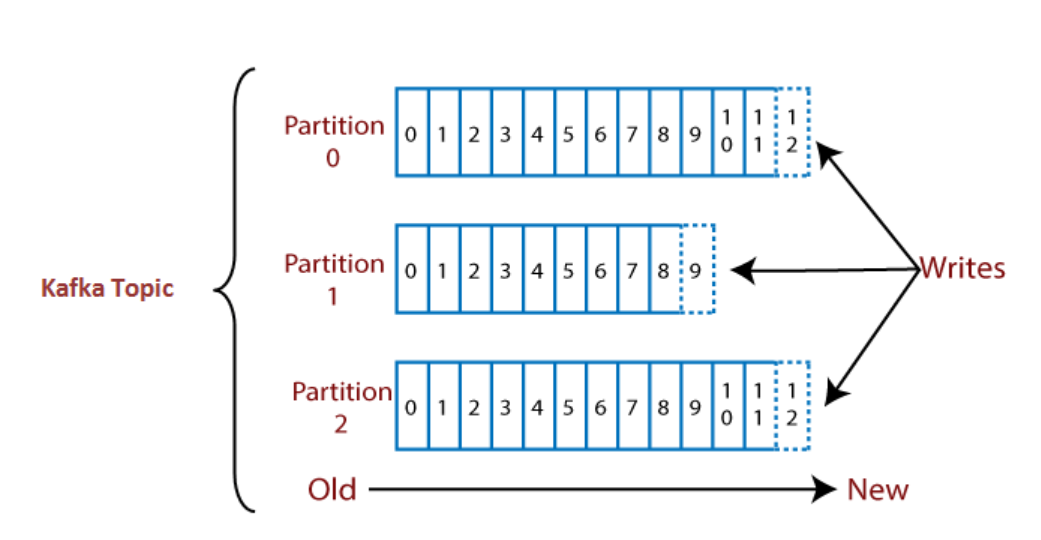
토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 만든 것을 파티션이라고 한다. 파티션은 초기 생성 후에 언제든지 늘릴 수 있지만 한 번 늘린 파티션 수는 절대로 줄일 수 없다.
그래서 메시지 처리량 혹은 컨슈머 LAG를 모니터링하여 조금씩 늘려가는 것이 중요하다. (LAG는 프로듀서가 보낸 메시지 수 - 컨슈머가 가져간 메시지 수)
파티션이 저장되는 위치를 오프셋(Offset)이라고 부르며 오프셋은 위 그림처럼 순차적으로 증가하는 숫자 형태로 되어있다.
8) 세그먼트(Segment)

프로듀서가 전송한 메시지가 브로커의 로컬 디스크에 저장되는 파일을 말한다. 브로커 내에 작은 메시지 단위인 토픽에서 파티션 안에 저장된 log 파일을 말한다.
컨슈머는 토픽을 컨슘하여, 해당 토픽 내의 파티션의 세그먼트 로그 파일에서 메시지를 가져오는 구조다.
'DevOps > Kafka' 카테고리의 다른 글
| Kafka Consumer의 Offset, Group Cordinator와 파티션 할당 전략 (0) | 2022.11.20 |
|---|---|
| Kafka Producer의 파티셔닝 동작 원리 및 전송 방식 (0) | 2022.11.20 |
| Local 테스트용 Kafka 브로커, 주키퍼 올리기 with Python (0) | 2022.11.18 |

