
devops
Kafka vs Kinesis vs SQS, Uber의 메시지 브로커 활용사례 본문
Apache Kafka
실시간 스트리밍 데이터 파이프라인 및 애플리케이션을 구축하기 위한 오픈 소스, 고성능, 내결함성 및 확장 가능한 플랫폼이다.
Apache Kafka는 스트리밍 데이터 저장소다. 스트리밍 데이터를 생성하는 애플리케이션(생산자)을 데이터 저장소에서 스트리밍 데이터를 소비하는 애플리케이션(소비자)과 데이터 저장소로 분리한다.
Apache Kafka의 분산 특성으로 인해 확장이 가능하고 노드 장애 시 고가용성을 제공한다. 주로 스트리밍 데이터를 분석하고 이에 대응하는 애플리케이션의 데이터 소스로 Apache Kafka를 사용한다.

Apache Kafka 는 레코드, 주제, 소비자, 생산자, 브로커, 로그, 파티션 및 클러스터와 같은 다양한 구성 요소로 구성된다.
레코드에는 키(선택 사항), 값 및 타임스탬프가 있을 수 있다. Kafka 레코드는 한 번 작성되면 수정할 수 없다. Kafka 주제는 레코드의 스트림이며 주제를 피드 이름으로 생각할 수 있다. 각 주제에는 디스크에 있는 주제의 저장소인 로그가 있다. 각 토픽 로그는 파티션 및 세그먼트라고 하는 것으로 더 세분화딘다.
Kafka에는 다음과 같은 네 가지 주요 API가 있다.
- Producer API: 데이터 스트림을 Kafka 클러스터의 주제로 보낸다.
- Consumer API: Kafka 클러스터의 주제에서 데이터 스트림을 읽는다.
- Streams API: 데이터 스트림을 입력 주제에서 출력 주제로 변환
- Connect API: 일부 소스 시스템 또는 앱에서 Kafka로 일관되게 가져오거나 Kafka에서 다른 것으로 푸시하는 커넥터를 구현한다.
* 최신 Kafka 버전의 완전한 유연성과 모든 이점을 제공하지만 관리에 더 많은 노력이 필요하다.
Amazon Kinesis
AWS Kinesis Streams를 사용하면 스트리밍 데이터의 대규모 데이터 수집 및 실시간 처리가 가능하다. 동일한 순서로 레코드를 읽거나 재생하는 기능뿐만 아니라 레코드의 순서를 보장한다.
- 최대 1MB의 레코드 크기 허용
- 메시지 수준이 아닌 샤드 수준에서 작동
- Auto Scaling 없음, 개발자는 샤드 사용량을 추적하고 필요할 때 Kinesis 스트림을 다시 샤딩 해야한다.
- 제한된 읽기 처리량 (샤드당 초당 5개의 트랜잭션)
- 스트림의 샤드 수가 최대 처리량을 결정한다.
- 여러 소비자를 단일 스트림에 연결할 수 있으며 각 소비자는 모든 레코드를 개별적으로 처리할 수 있습니다(shard-iterator 덕분에).빅데이터를 실시간으로 처리하는 AWS(Amazon Web Service)다.
Kinesis 고유의 주요 기능은 시간당 수백 테라바이트의 대용량 데이터 스트림 을 처리하는 기능이다. 이는 운영 로그, 소셜 미디어 피드, 게임 내 소액 거래 또는 플레이어 활동 또는 금융 거래와 같은 소스에서 지속적으로 캡처될 수 있다. 이전 기술에 비해 장점은 특정 앱의 개발 프로세스를 단순화할 수 있다는 것이다. 이는 스트리밍 데이터로 Kinesis의 실시간 운영 의사 결정을 통해 이루어진다.
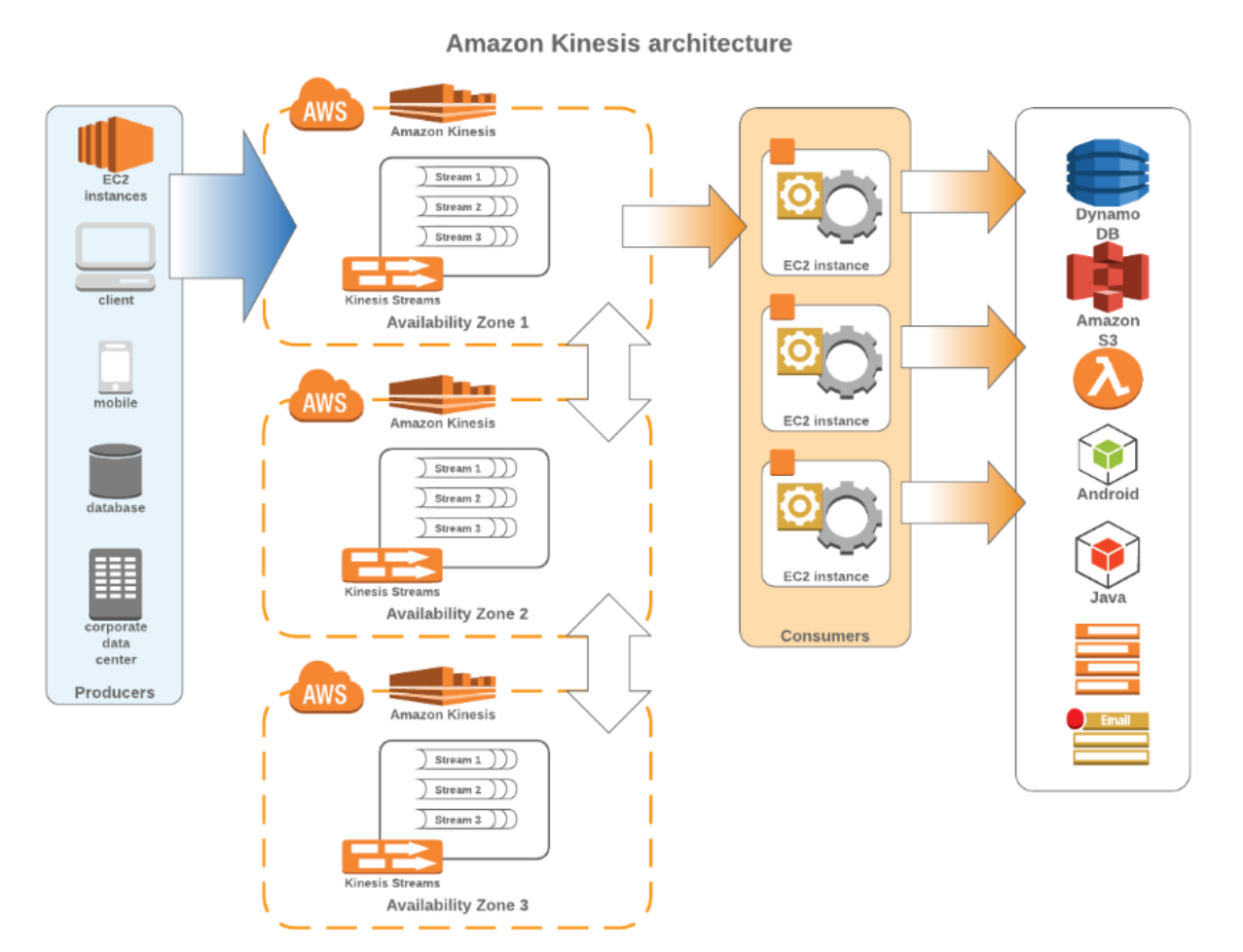
데이터 생산자, 데이터 소비자, 데이터 스트림, 샤드, 데이터 레코드, 파티션 키 및 시퀀스 번호와 같은 주요 개념으로 구성된다.
샤드는 Amazon Kinesis 데이터 스트림의 기본 처리량 단위다. 데이터 생산자는 데이터 레코드가 생성될 때 내보내고 데이터 소비자는 스트림의 모든 샤드에서 데이터가 생성될 때 데이터를 검색한다. 스트림은 샤드의 논리적 그룹인 반면 레코드는 Amazon Kinesis 스트림에 저장된 데이터 단위다. 마지막으로 파티션 키는 일반적으로 사용자 ID 또는 타임스탬프와 같은 의미 있는 식별자이고 시퀀스 번호는 각 데이터 레코드에 대한 고유 식별자다.
* Kafka를 관리할 자체 리소스가 없는 사람들을 위해 스트리밍 기술을 도입하는 프로세스를 단순화하지만 Kinesis에는 Apache Kafka보다 훨씬 더 많은 제한이 있다.
Amazon SQS
AWS Simple Queue Service(SQS)는 분산 애플리케이션 구성 요소 간에 메시지를 저장하고 데이터를 쉽게 이동할 수 있도록 안정적이고 확장성이 뛰어난 서버리스 호스팅 대기열을 제공한다.
- 최대 256KB의 비교적 작은 메시지 크기 허용
- 각 메시지는 독립적으로 처리될 수 있다.
- 대기열에서 읽는 작업의 수를 조정하여 읽기 처리량을 동적으로 증가시키는 자동 조정
- 메시징 시맨틱(예: 메시지 수준 승인/실패) 및 메시지 가시성 시간 초과를 제공한다.
- 표준 대기열의 경우 인플라이트 메시지 수에 대한 120,000 개 제한 및 FIFO 대기열의 경우 20,000개 제한
Kinesis vs SQS
메시지 보존
- Kinesis — 기본적으로 24시간 동안 레코드를 저장하고 최대 7일 동안 스트리밍 데이터를 유지할 수 있습니다.
- SQS — 메시지 보존 기간을 1분에서 14일까지 구성할 수 있으며 기본값은 4일입니다.
메시지 재시도
- Kinesis — 배송 보장 없음, 데이터가 존재하는 한 서비스 소비 데이터 재시도 가능, 소비자가 데이터를 제거하지 않음, 재구동 항목의 경우 주문도 보장됨
- SQS — 최소 1회 배달 보장, 메시지 보존 기간에 따라 메시지가 최대 수명에 도달할 때까지 미확인 메시지를 계속 다시 게시합니다.
장애 처리
- Kinesis — 즉시 사용 가능한 DLQ( Dead Letter Queue ) 없음, 스트림을 사용하는 모든 애플리케이션은 자체적으로 오류를 처리해야한다.
- SQS — 소비자가 가시성 제한 시간 내에 메시지를 처리하지 못하면 메시지가 구성된 DLQ로 전송되고 SQS에서 다시 수신될 수 있다.
소비자 수
- Kinesis — 여러 소비자 기능 지원, 여러 소비자가 동일한 데이터 레코드를 동시에 처리하거나 동일한 소비자가 다른 시간에 처리할 수 있다.
- SQS — 메시지가 승인되면 대기열에서 삭제되며 한 번에 단일 소비자만 지원한다.
레코드 순서
- Kinesis — 샤드 내에서 순차 처리를 지원하지만 샤드 간의 어떤 종류의 순서도 보장할 수 없다.
- SQS — 표준 SQS 대기열은 순차 처리를 보장하지 않지만 FIFO 대기열은 지원하지만 제한 사항이 있다.
레코드 라우팅
- Kinesis — 관련 레코드를 동일한 레코드 프로세서로 라우팅할 수 있음
- SQS — 라우팅 지원 없음
기타 AWS 서비스 지원
- Kinesis — 스트림 레코드를 Amazon S3, Amazon Redshift, Amazon ElasticSearch, Splunk, AWS Lambda와 같은 서비스로 직접 보낼 수 있다.
- SQS — AWS Lambda를 통해 다른 서비스를 통합할 수 있다.
사용 사례
- Kinesis — 로그 및 이벤트 데이터 수집, 실시간 분석, 모바일 데이터 캡처, 사물 인터넷 데이터 피드
- SQS — 애플리케이션 통합, 마이크로 서비스 분리, 집중적인 백그라운드 작업에서 실시간 사용자 요청 분리, 향후 처리를 위한 일괄 메시지
https://medium.com/nerd-for-tech/system-design-choosing-between-aws-kinesis-and-aws-sqs-2586c814be8d
System Design — Choosing between AWS Kinesis and AWS SQS
In this blog post, I explore AWS Kinesis vs AWS SQS, showing the benefits and drawbacks of each system and which one to prefer based on…
medium.com
https://www.softkraft.co/aws-kinesis-vs-kafka-comparison/
AWS Kinesis vs Kafka comparison: Which is right for you?
I was tasked with a project that involved choosing between AWS Kinesis vs Kafka. The choice, as I found out, was not an easy one and had a lot of factors to be taken into consideration and the winner could surprise you. In this article I will help to choos
www.softkraft.co
Disaster Recovery for Multi-Region Kafka at Uber
Uber는 하루에 수조 개의 메시지와 수 페타바이트의 데이터를 처리하는 세계 최대 규모의 Apache Kafka 배포를 보유하고 있다.

그림 1에서 볼 수 있듯이 우버는 Apache Kafka를 Uber 기술 스택의 초석으로 포지셔닝하여 그 위에 복잡한 에코시스템을 구축하여 다양한 워크플로를 지원한다.
여기에는 Rider와 Driver 앱에서 이벤트 데이터를 전달하는 pub/sub 메시지 버스, 스트리밍 분석 플랫폼, 데이터베이스 변경 로그를 다운스트림 구독자에게 스트리밍 등 모든 종류의 데이터 수집이 포함된다.
Apache Kafka를 기반으로 확장 가능하고 안정적이며, 뛰어난 성능과 함께 사용하기 쉬운 메시징 플랫폼을 제공하기 위해 여러 노력이 있었다.
이 기사에서는 클러스터 다운타임과 같은 재해 복구 과정과 함께 Uber에서 다중 지역 Apache Kafka 인프라를 구축하는 방법을 설명한다.
Multi-region Kafka at Uber
비즈니스 탄력성과 연속성을 제공하는 것은 Uber의 최우선 과제다.
재해 복구 계획은 정전, 치명적인 소프트웨어 오류 및 네트워크 중단과 같은 자연 재해 및 인재의 비즈니스 영향을 최소화하기 위한 목적으로 구축된다.
우버는 서비스가 지리적으로 분산된 데이터 센터에 백업과 함께 배포되는 다중 지역 전략을 사용합니다. 한 지역의 물리적 인프라를 사용할 수 없는 경우에도 서비스는 계속 다른 지역에서 계속 실행될 수 있다.
지역 장애를 대비한 데이터 중복성을 제공하기 위해 다중 지역 Kafka 설정을 아키텍처화했다. 오늘날 Uber 기술 스택의 많은 서비스는 지역 수준 장애 조치를 지원하기 위해 Kafka에 의존한다.
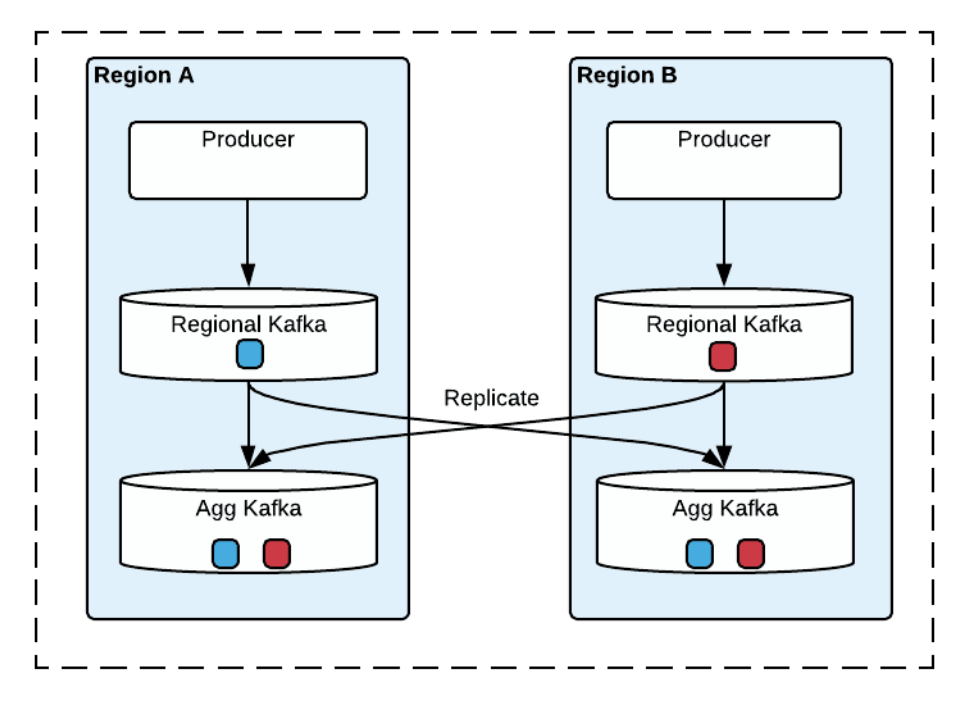
위는 다중 영역 Kafka의 아키텍처를 보여줍니다. 클러스터에는 두 가지 유형이 있다. 생산자는 지역 클러스터에 로컬로 메시지를 게시하고 Regional Kafka(Region Cluster)의 메시지는 전역 보기를 제공하기 위해 Agg Kafka(Aggregate Cluster)에 복제됩니다. (도식의 단순화를 위해 그림 2는 두 지역의 클러스터만 나타냄)
각 지역에서 생산자는 성능향상을 위해 항상 로컬에서 생산하고, Kafka 클러스터를 사용할 수 없는 경우 생산자는 다른 지역으로 장애 조치하고 해당 지역의 Regional Kafka(Region Cluster)로 생산한다.
이 아키텍처의 핵심 부분은 메시지 복제다.
메시지는 Regional Kafka(Region Cluster)에서 지역 전체의 Agg Kafka(Aggregate Cluster)로 비동기식으로 복제된다. 강력하고 안정적인 방식으로 Apache Kafka 데이터를 복제하기 위한 Uber의 오픈 소스 솔루션인 uReplicator를 구축했다.
* uReplicator는 Kafka의 MirrorMaker의 원래 디자인을 확장하여 매우 높은 안정성, 데이터 손실 없음 보장 및 작동 용이성에 중점을 두고 있다.
Consuming from multi-region Kafka clusters

다중 지역에서 소비하는 것은 생산하는 것보다 더 복잡하다. 다중 영역 Kafka는 두 가지 유형의 전체 활성을 지원한다. 일반적인 소비 유형은 활성/활성으로 소비자가 각 지역의 집계 클러스터에서 동일한 주제를 독립적으로 소비한다.
오늘날 Uber의 많은 애플리케이션은 활성-활성 모드를 사용하여 다중 지역 Kafka에서 소비하고 다른 지역의 해당 애플리케이션과 직접 통신하지 않는다. 지역이 실패하면 Kafka 스트림이 두 지역에서 모두 사용 가능하고 동일한 데이터가 포함되어 있는 경우 다른 지역의 상대방으로 전환한다.
'DevOps' 카테고리의 다른 글
| DevOps에서 모니터링(Monitoring) 정의 및 분류 (0) | 2022.07.13 |
|---|---|
| 가변적 인프라, 불변적 인프라 차이와 Terraform 선언적 방식과 상태 (0) | 2022.06.24 |
| 동기식 요청/응답 통신 REST, 메시지 브로커를 통한 비동기 통신 (0) | 2022.06.17 |
| API 디자인과 프로세스 통신, JSON (0) | 2022.06.17 |
| 블루/그린, 롤링, 카나리 배포 (0) | 2022.06.07 |



